2023年11月10日
エグゼクティブのための生成AI講座 その2
―ニューラルネットワークによる単語の分散表現―

LLMの発展をもたらした技術要素
イノベーションという概念を産み出したシュンペーターが実際に使った言葉は新結合であった。既存の技術やアイディアなどが結びつくことで新しいものが創造されるという考え方である。自然言語モデルのイノベーションにおいても、いくつかの重要な技術要素の発展とこれらの新結合があった。
その代表的なものとして、①言語の数値化・ベクトル化(分散表現あるいは埋め込み表現)へのNN学習手法の応用、②時系列データを扱えるNN(RNN)をLLNに応用、③系列変換モデル(seq2seq)に対するEncoder/ Decoderモデルの応用、④文意をとらえるAttention機構の導入、⑤スケール則の発見(モデルやデータの規模拡大による性能向上の法則性)があげられる。まず、言語の数値化から説明する。
言葉を数値化し関係性を表現する
モデルは数字を使う。そのため自然言語モデルでは、まずは言葉を数値化する必要がある。単純なアプローチとして単語にIDを振る方法が考えられるが、膨大な量になるだけでなく、文章に内在する単語間の関係性をどのように効率的に表現するかという問題に直面する。仮に単語が100万語あって、単語1と残りの単語2~単語1,000,000までとの関係を個々に数字で表現していくと、関係性を表現する情報は100万x100万の行列となり非常に効率が悪い。当初は、実際の文章に出てくる単語の「離接」関係をそのまま情報として用い、単語をベクトル表現化するアプローチが採られた(1)。
エポックメイキングになったのはword2vecというモデルの登場である。これは、前後の複数の単語から間にある単語を推測する、あるいはある単語から前後の複数の単語を推測するという推論問題をNNに学習させ、推定されたパラメータから各単語をベクトル表現する手法である(2)。ベクトル化することで以下のような言葉の計算が可能となる。
東京-日本 = パリ-フランス
これは、概念上の情報処理ではなく、数字の計算として成立している。各単語が2次元空間に埋め込まれてベクトル化されているとしよう。日本やパリという単語は図1に示したベクトルとして表現できる。定式の左辺は図中の太い青矢印ベクトルであり、これは右辺(オレンジで示した2つのベクトルの差)と同一となっている。青矢印は首都という単語のベクトル表現に相当する。学習対象のコーパスに「日本の首都は東京である」「フランスの首都はパリである」といった文章が存在することで、5つの単語の関係性を分散表現で表すことができる。
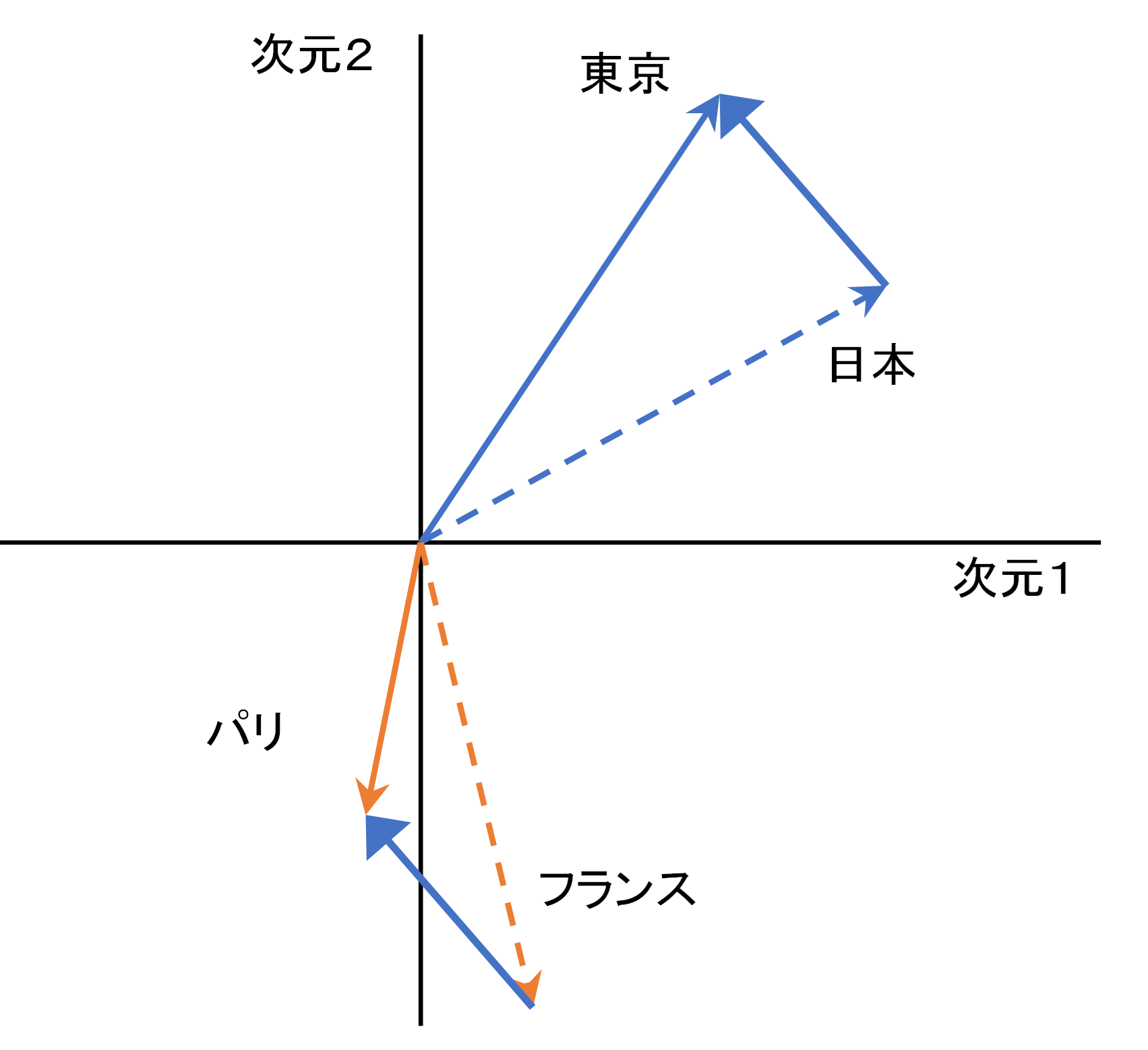
図1 パリ = フランス+(東京-日本)
筆者作成
ここでは簡単化のために2次元とし、東京やパリという単語を図1中で(x1, x2)とベクトル表現したが、数十万の単語の関係を2次元に押し込むのは精度の面で困難であり、実際には数百~数千といった次元への圧縮が利用される。また、上の式も近似的に成立するに過ぎない。
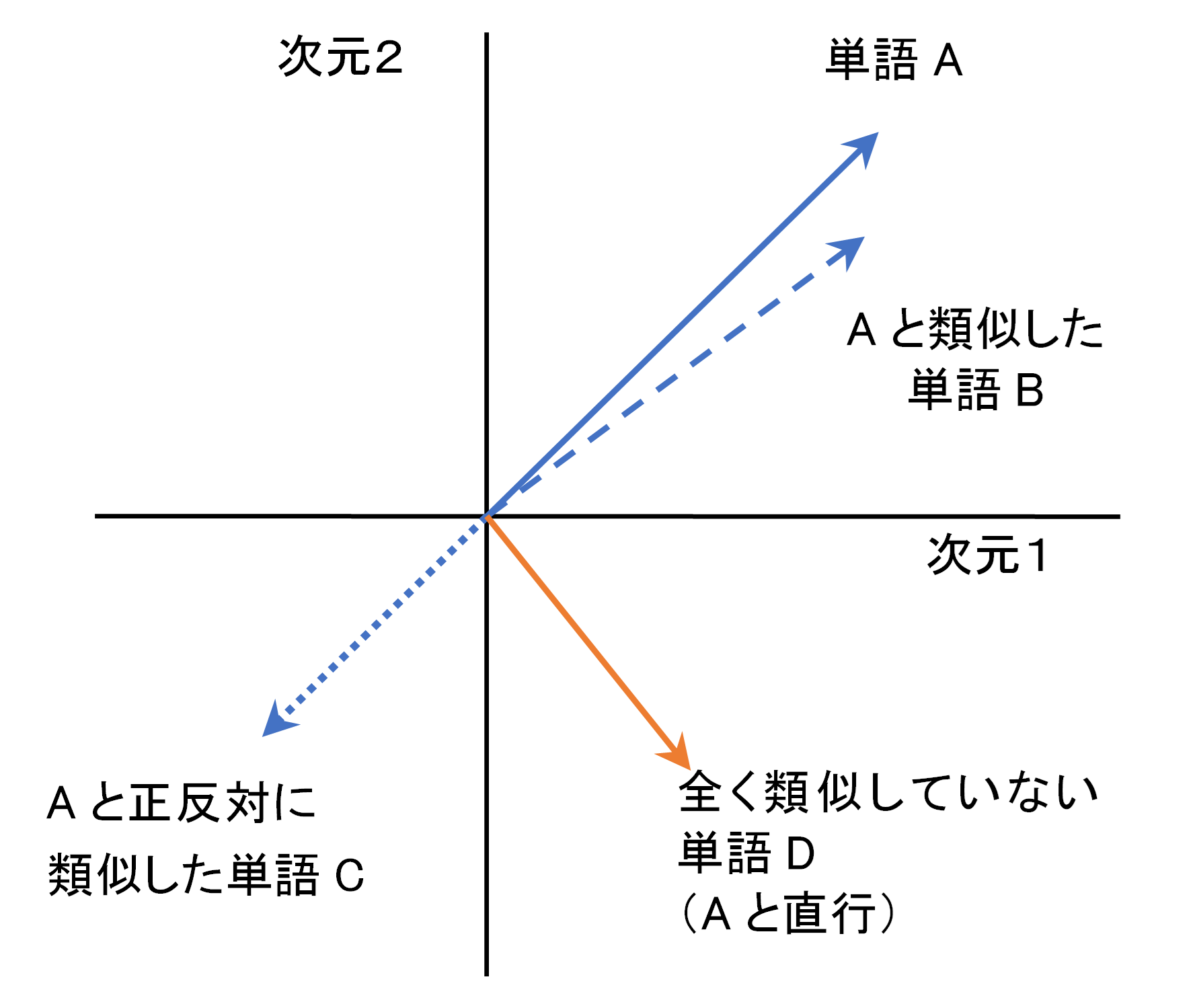
図2 二次元空間で測った単語の類似性
筆者作成
ベクトル化により単語の類似性の計測も図2のように可能となる。単語が数値化されているのでコサイン類似度や空間内での近傍関係を測る指標を活用することもできる。ECや映像音楽の配信などで各種の推薦サービスが提供されているが、これらは画像や商品特性をデジタル情報化(ベクトル化)したうえで、類似度を計算するという技術によって支えられている。
word2vecと転移学習
word2vecは転移学習を可能とした。単語の分散表現における転移学習とは、ある学習セットで作成したベクトル表現は、その学習セットが高い汎用性を有するものなら他の文章にも適用できる(転移可能である)ことを指す。日本語Wikipediaのような大規模コーパスで学習したword2vecの結果は、再計算することなくそのまま一般的な文章に適用できる(3)。
見方を換えると、特殊な文章から成るコーパスには適用しにくく、学習し直しが必要となる。その場合も、言語の本質的な特性が変わっているわけではないので、ゼロから学習する必要はない。転移学習は、LLMにおいてもプレトレーニング(事前学習)とファインチューニングという実用上、非常に便利な特性をもたらしており、別稿で後述する。
なお、汎用性があるword2vecが多数公開されており、NNの学習なしでそのまま使うことができる(単語を入れるとベクトル表現に変換してくれる)。次元数は様々な設定が可能であるが、単語間の関係性を表現するためには数百次元程度のものが使われることが多い。
先に紹介した不効率な行列表現は100万x100万であったが、単語数を同じ100万とするとベクトル表現(行列表現)は100万x数百まで圧縮される。単語の分散表現ではこうした次元圧縮によって、LLMの性能向上や計算コスト削減をもたらしている。
word2vecの限界
言語のベクトル表現に効率性をもたらしたword2vecであったが、学習対象のコーパスに含まれる単語数が100万のように大きなものになると計算量は膨大なものとなる。このため、Negative samplingのような計算の効率化手法が必要とされた。
また、単語の隣接関係に基づく推論問題から算出されるため、位置関係より更に複雑な文脈の流れや、複数の意味や読み方を持つ文脈依存の多義語を扱うのが不得意であった。なによりも、word2vecは言語を生成するモデルではなく、単語をベクトル表現する装置であり、生成AIの実用化はその後のLLMの発展があってのことであった。
LLMの発展には、単語が意味ある順序で並んでいるという文章の時系列データ的特性を表現するモデルが必要であった。株価の時系列データを並び替えると意味がなくなるのと同様、単語も文書内でランダムに並び替えることはできない。その意味で文書は単語の時系列データである。次の記事では、言語生成モデルとしてのLLM発展の起点のひとつとなったRNNを説明する。自然言語モデルに時系列データを扱えるNNを適用することで言語生成モデルを作り出している。
なお、ベクトル表現のモデルは言語生成のLLMと並行して発展を続けており、有名なものとしてはFastTextやELMoがある。ELMoではRNNの拡張版であるLSTM(後述)を用いて、文章全体の情報を基づき単語をベクトル表現化し、かつ1つの単語に3つのベクトル表現(各々1024次元)をもたせることで多義語対応などパフォーマンスを改善している。ELMoは他のベクトル表現モデルを補完する用途で提唱されたが、単独で利用することもできる。
ChatGPTで知られるOpenAIもベクトル表現に特化したLLMを開発し続けている。例えば、GPT-4や3では、text-embedding-ada-002というベクトル表現に特化した軽量高速のモデルが用いられている。LLMにおいて言語や文書のベクトル表現化は、LLMの入り口(と出口における数値の言語復号)で行われる言語の数値化という極めて重要な役回りを果たしている。
text-embedding-ada-002の画面イメージ
筆者作成
(その3に続く)
(1) 単語がどのような隣接関係をもって頻繁に登場するかを数えた共起行列や、その改善版のPMI(相互情報量:Pointwise Mutual Information)は、カウントベースのベクトル表現と呼ばれる。文章を構成する単語数に相当する高次元行列となるため、特異値分解という次元圧縮方法が使われる。
(2) NNへのインプットには各単語に割り当てられたone hotベクトルが用いられる(単語1は{1,0,0,…}、単語2は{0,1,0,…}、単語3は{0,0,1,…}、以下同様)。これは、単語にIDを振るのと実質的に同じである。各ベクトルは直行関係にあるため、one hotベクトルの組み合わせで他のone hotベクトルを表現することはできない。このためNNのパラメータ(行列)に単語間の関係情報を集約することができる。推論問題はこの行列情報を得るための手段として設定されている。word2vecはシンプルなNNを用いており、推論結果表示のための確率表現以外のところでは行列演算を行っているにすぎない。図1に示したような単語ベクトルの線形演算が可能であるのは、このようなモデルの線形性に起因する。
(3) 一般には、転移学習とは、あるタスクのために学習させたモデルが、他のタスクにも転用可能であることを指す。例えば、文章の分類問題や要約作成、翻訳、賛成反対の判断、感情分析、対話生成など、LLMには様々なタスクが考えられるが、翻訳用に学習させたLLMが対話生成や要約作成にも高い能力を発揮するという汎用性を有する場合がある。あるいは、比較的少ない追加学習データや学習コストによって高い能力を持たせることが可能となる。この特徴はLLMの実用化に重要な役割を果たしている。