2023年11月10日
エグゼクティブのための生成AI講座 その1
―LLM(大規模言語モデル)とは何か―

生成AI、とくにLLM(大規模言語モデル)を金融ビジネスに活用し、1)既存業務の効率化や高度化を図ること、2)新しい金融サービスを創造すること。日々様々なニュースリリースが出ているように、多くの金融機関がこの課題に取り組んでいる。
競争力の強化や新しい収益源の模索に直結するものであり、他社がやって自社がやらない状態が続けば、やがては競争力や顧客基盤、ひいては収益力が失われていく。2000年代初期のネットバンキングやネット金融サービスの幕開け期に近いのかもしれない。
生成AIは、ハイプサイクルの盛り上がりと幻滅期を通過しつつ、スマートフォンやキャッシュレス決済のように着実に企業活動や社会生活に定着し、金融ビジネスにおいても当たり前のように使われる技術となっていこう。
金融機関では「生成AIへの取り組みを」というトップダウンの号令がかかり、各事業部門も何に使えるのか、どのようなビジネスモデルが可能となるのか、技術キャッチアップと活用のトライアルを続けている。こうした事業アイディアや実装の試み、その成果を取り上げた記事も多く出ている。
その一方で、生成AIがどのような仕組みで動いているのか、どうやって顧客向けサービスを提供するシステムを構築すればいいのか、そうした技術面に踏み込んだ記事を経営層やビジネス現場に向けて提供したものは少ない。
ネットには膨大な一次情報(技術開発者/社が提供する使用法や解説)や利用者が作成した解説記事があるが、殆どは開発者向けのものである。書籍としてChatGPTの使い方指南書などが多数出版されているが、個人が生産性を向上させる目的のものが多く、ビジネス展開というサービス提供側の視点に立ったものは少ない。
そこで本稿では、エグゼクティブ向け・ビジネスパーソン向けに、LLMとは何か、どのような技術が使われ、どう実装されているのかを、技術面に踏み込みながら、かつできるだけ平易に解説することを試みた。紹介すべき情報量が多いため、シリーズ形式で掲載する。
LLMとは
LLMとは何か。端的にいうと、この言葉がきたらこんな言葉が続く可能性が高い、この話の流れからはこのような展開になるだろう、こんな話や指示が振られているからこの内容を返すのが適切そうだ、そうした適切な言葉の繋がりを確率計算で求め、次にくる言葉を連続的に生成することで文章を作り出すモデルがLLMである。本当にそのようなアプローチで上手く文章が作れるのか直感的には疑問であるが、とても上手くいったというのがLLMの衝撃的な誕生と発展のストーリーである。
こうしたアプローチが可能となるためには、膨大な文章を学習情報として収集し、文章のパターン性を精緻に学習する必要がある。ある話の流れがあって次にくる言葉を適切に選ぶといった場合、その「適切」とは何を意味するのか。
教師(正解)あり学習モデルでは、学習用の膨大な文章において言葉があるパターン性をもって並んでおり、その並び方、登場の仕方、組み合わせ方、前の受け方、後ろへの続き方などを上手く模倣できることが「適切」を意味する。次にくる確率が最も高い言葉を適切に選ぶようモデルのパラメータを設定していくことが自然言語モデルにとっての「学習」であり、人間の学習のイメージのように知識や体系を学ぶ・記憶する行為とは概念的に異なる。
画像情報からそれが何であるかを判別する学習では正解データが必要となる(犬の写真に犬というラベル、トイプードルの写真にトイプードルというラベル)。この膨大な情報を学習用に作成するのは大変であるが、文章サンプルでは次にくる言葉は既に分かっている。しかも、切る場所を変えれば1文で多くの学習用問題が作れる。
日本語Wikipediaでは140万近い項目について膨大な解説文がある。Wikipediaは文章や言葉の使い方を大規模に収集した「コーパス」の代表例としてLLMの学習に利用されてきた。また、ネットにある膨大な文章を集めて整理した更に大規模なコーパスも複数ある。例えば、国立情報学研究所(NII)が10月20日に公開したLLM-jp-13Bでは、パラメータ数130億、学習データとしては約3000億トークンを利用している(トークンは後述、日本語では1トークンは概ね1文字に相当)。
まとめると、LLMとは、自然言語を生成するプログラムを、大規模な学習データを用いて、大規模なモデルとして作成したものである。
ChatGPTとLLMの関係
生成AIではOpenAI社のChatGPTが有名である。OpenAI社のWebサイトを訪れ、Webアプリケーションサービスとして利用する。同社は他の様々なLLMを開発・提供し続けており、ChatGPTサービスの裏側で動いているのはこうしたLLMであり、その最新型がGPT-4である。SaaSとしてWebアプリケーションサービスを利用する以外に、OpenAI社のサーバにAPIでアクセスし、特定のLLMを指定して利用することもできる。
LLMには、チャットが得意なもの、日本語が得意なもの、特定専門分野に特化したもの、文章を数字に置き換えるという前処理を行うのが得意なものなど様々な種類がある。また、例えばGPT-3といってもモデル規模や性能進化に応じて種々なバリエーションが存在している。GoogleやMetaほか様々な企業がLLMを開発しており、日本でも日本語の文章処理能力を高めた多くのLLMが開発され続けている。
モデルとパラメータをオープンソースとして公開したLLMも少なくない。こうしたLLMは、パブリッククラウドや自前のサーバにシステムを構築することができる。軽量なものはノートPCでも稼働する。オープンソースとして公開されてはいないがパブリッククラウド上でLLMを活用したシステムを構築できるようサービス提供されているものがある。Azure OpenAIがその代表例である。
ところで、ChatGPTが注目され始めた当初、Google検索エンジンのように調べものに使った結果、嘘を教えられた、あれはダメだという話がよく聞かれた。LLMは文章の展開が尤もらしくなるよう単語や文を並べているだけであり、その尤もらしさが事実である保証はない。
学習に用いたコーパスにその事実に関する記述が大量にあり、AといえばBが出てくるように学習結果がパラメータに反映されているのでなければ、文章として尤もらしいが内容は嘘という現象は当然生じる。元になる情報がなければ適切な回答は返せない。こうした汎用LLMの限界を改善していく方法として様々なアプローチが提案され、実用化されている。この話はシリーズの後半で解説する。
LLMのベースはニューラルネットワーク
ここまでの説明で「モデル」という言葉を使ってきたが、LLMのベースにあるモデルの先祖はニューラルネットワーク(以下、NN)である。1980年代前半に登場し、第二次AIブームを牽引したNNは、脳のシナプスの構造を単純化して表現したモデルであった。
次図のようにインプットとアウトプットを中間層を使って繋ぎ、アウトプットが正解と合致するようパラメータを調整する(学習する)仕組みである。例えば、植物のアヤメの特徴を現すデータとして花びらやガク片の長さと幅のデータがあったとする。これがインプットで、アウトプットがアヤメの種類である。花びらやガク片のデータから種類を正しく言い当てられるようNNのパラメータが推計される。
金融分野ではデフォルトの判別分析や格付けモデルがこれに近く、データによる判別機械といえる。ちなみに判別分析は機械学習の最も代表的な用途であり、NN以外にも様々なモデルが考案されている。
計量経済学でも質的選択モデル/離散選択モデルとして昔から開発されてきたが、NNは関数の非線形性の表現力が高い点が注目された。筆者は1990年代前半に、金融政策反応関数(当時は公定歩合の上げ/下げ/据え置き)にNNを適用し、政策変更を高い精度でトレースするモデルを推計したことがあり、論文中でその柔軟な非線形性を可視化している(リンク先の図17・18)。
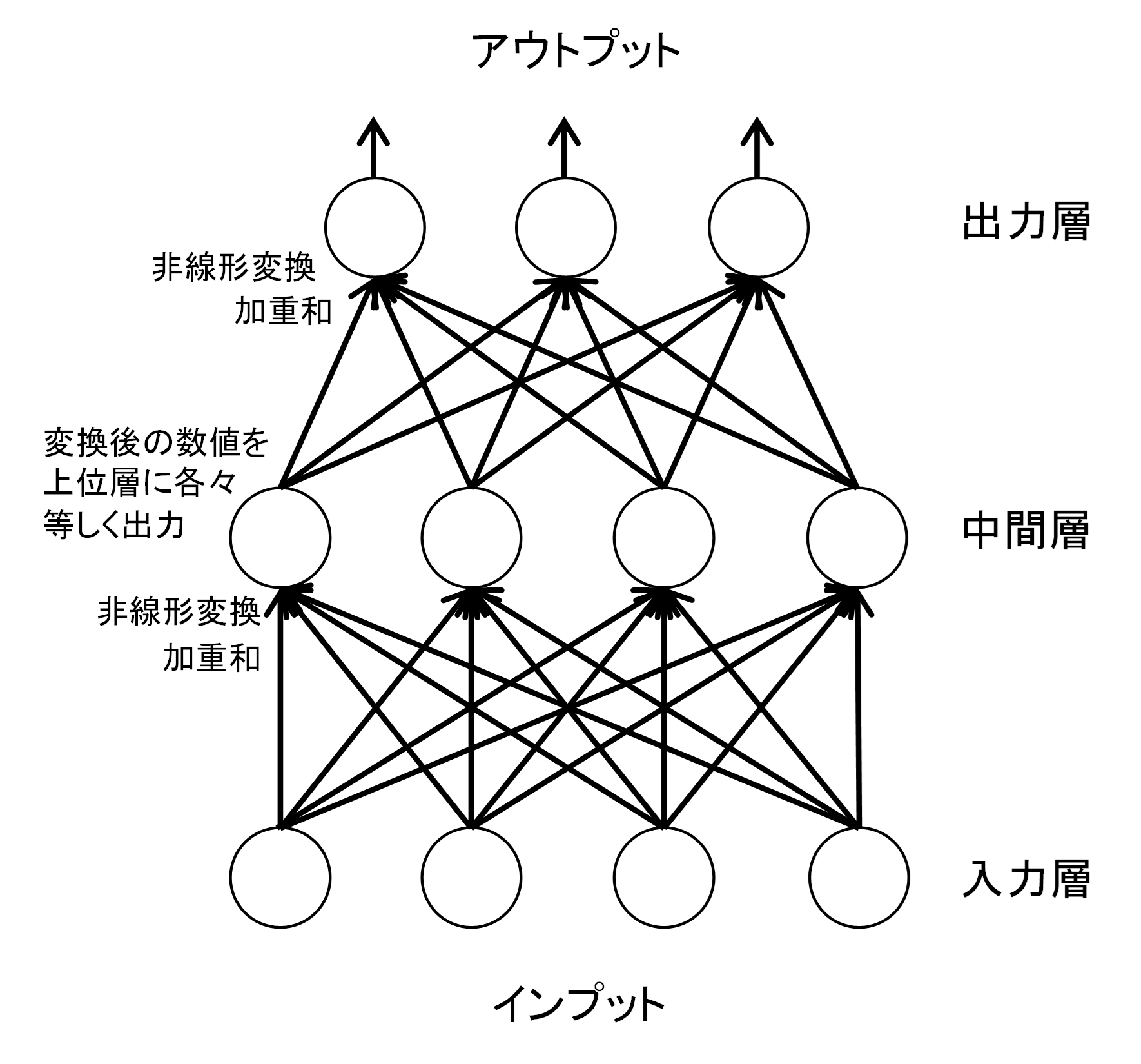
ニューラルネットワークの基本構造
筆者作成
NNのインプットやアウトプットは、数値もしくは数値化された画像や音声が中心であった。例えば、アウトプットについて正常先を1、破綻懸念先を4とインデックス化し、インプットを企業のPL/BSの様々な指標などから集めてきたような信用リスクモデルをイメージすると解りやすい。画像も数値化が容易である。1万画素の24ビットカラー画像は、各画素をRGB(Red/Green/Blue)3色の0~255段階色調で表現することによって数値化することができる。
インプットとアウトプットを繋ぐのは四則演算に過ぎない。指数と分数を使うことで非線形性が導入されているが、各過程の計算は非常にシンプルである。インプット変数を様々なウエイト(パラメータ)を付けて合算し、それを非線形関数で変換したものを中間層へのインプットとし、これを次の中間層への出力として同じことを繰り返し、最終的にアウトプット層から出力がなされる。単純な関数を大量に組み合わせることで複雑な関数を作りだす仕組みとなっている。このため、モデルは多くのパラメータを持つ。
NNは中間層の階層を増やしたり、インプット要素を増やしたりするとモデルの精度や表現力が高まることが期待されたが、計算技術やコンピュータの計算能力の制約からそうはならず、80年代の第二次AIブームは徐々に収束していった。その後、長いAI冬の時代が訪れる。
2000年代後半にこの限界をブレイクする技術が現れた。ディープニューラルネットワーク(DNN)であり、これが第三次AIブームを切り開いた。中間層を数十も積み重ねてもパラメータの学習が上手く行われる手法の開発や計算能力の確保によって、NNのパフォーマンスが飛躍的な向上を辿り始めた。LLMにはNN/DNNを発展させたモデルが利用されている。
次のレポ―トでは、自然言語モデルにNNを適用する際の鍵となった要素を解説し、LLMがどのように発展し現在のような高性能を持つに至ったかを順に紹介していく。
(その2に続く)