2026年1月26日
すべての新入社員をAI人材へ
―垂直離陸型SBIグループ生成AI研修(後編)―

すべての新入社員をAI人材へ
後編では、研修プログラムの内容を詳細に紹介していく。短期集中の垂直離陸型研修は、4つの講義と自習で構成されている(図表1)。前半の2つが主に座学であり、その後のPython事前自習期間をはさんで、後半2つが開発環境を用意してのハンズオンセッションとなっている。研修講義に用いたマテリアルと講義ビデオは、イントラネットのSBI AI Digital PortalでSBIグループ内に公開されており、研修対象者以外にも参照可能となっている(図表2)。
|
第1講 |
生成AI基礎概論 |
|
事後課題 |
第1講の復習と深堀りのための課題 |
|
第2講 |
クラウドサービスの基礎 |
|
事前学習 |
次講準備:Pythonのローカル環境セットアップと基本コーディング |
|
第3講 |
APIでLLMを利用:仮想環境での業務ユースケースのハンズオン |
|
事前学習 |
次講準備:UNIX基本コマンド、関数、クラス、メソッドの理解 |
|
第4講 |
マルチエージェントAI作成とWebアプリケーションへの実装 |
図表1 生成AI研修の構成
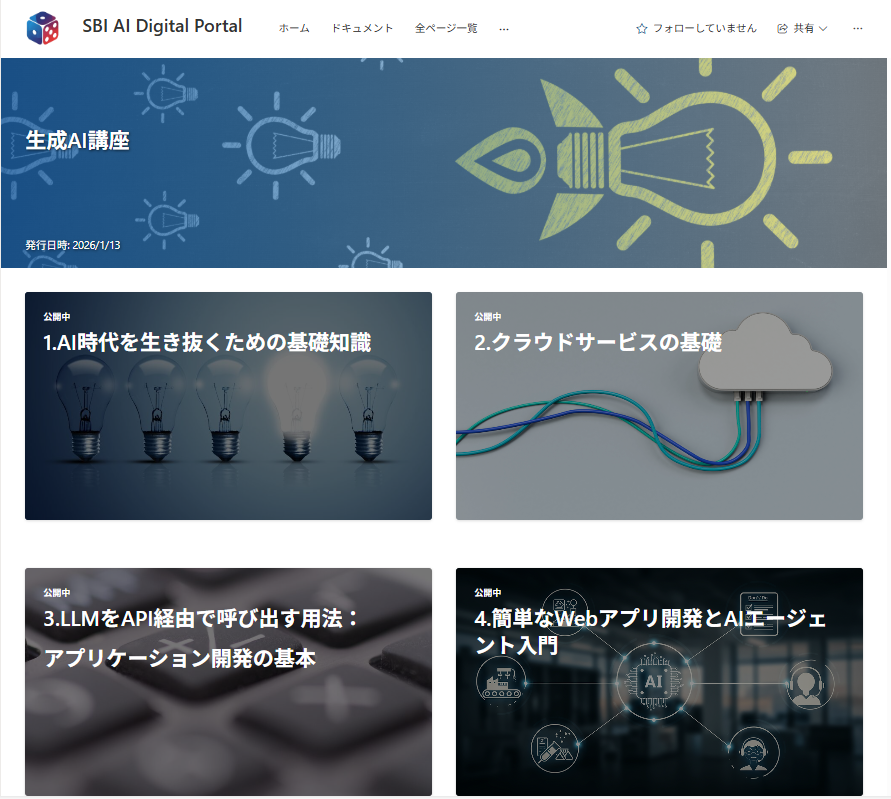
図表2 ポータルサイトの案内ページ
第1講
第1講では、導入として生成AI概論の講義を行った。講師は、入社2年目のAI・デジタル戦略推進部のスタッフである。本講義では、座学だけに止まらず、その場で実践してみるハンズオンを組み合わせることで、1)AI活用に対する心理的ハードルを引き下げ、2)各参加者の実務の場での再現可能性を高めるとともに、3)講義中の集中力維持や脱落防止に配慮した構成としている。
まず、広義AIの歴史的背景から最新の技術動向までを概観し、学びの動機付けのため、AIが現代のビジネス環境にどのような革命的変化をもたらしているかを解説した。
次に、生成AIアプリケーションの構成要素として、Webアプリケーションの仕組み、LLM(大規模言語モデル)、API、クラウド、認証認可などの基本概念を説明した。AI、生成AI、機械学習、深層学習、LLMなどのコンセプトも混乱しやすいので整理を行っている。
生成AIにできること(何を生成するか)を網羅的に紹介し、その具体例として、一般に提供されているサービスの代表的事例を紹介した。AI検索エンジン(Perplexity、Genspark)や、汎用型RAGとしても利用可能な資料読解支援アプリ(NotebookLM)、画像や動画、音楽、漫画の生成サービス、コーディング支援などである。金融ビジネスに関連する代表的な業務活用事例をあげ、新入社員が各々従事しているビジネスのなかにも多くの活用可能領域があることを発見してもらった。
次に、利用の注意点として、倫理面からの問題点(バイアス、公平性、不適切な情報拡散、責任境界など)と、信頼性(ハルシネーション、学習情報のリミットデイト、説明不可能性)、プライバシー、セキュリティ、知財・著作権などを解説している。こうした一般論に続いて、SBIグループ内で策定・運用されている生成AI利用ガイドラインの解説を行い、業務運営に活用する場合の注意すべき点を学んだ。
ハンズオンの導入として、AIとの対話技術である「プロンプトエンジニアリング」を体験してもらった。具体的には、メール要約や返信草案作成、議事録作成など、新入社員がすぐに活用できそうな題材を取り上げている。業務で使える具体的なシナリオを通じて、AIから意図した通りの高品質なアウトプットを引き出すための「プロンプトの型」の習得を目標としている。
その際、単に指示を出すだけでなく、明確な役割設定、背景情報の付与、出力形式の指定、そして改善を繰り返す反復的アプローチを体験し、AIを駆使するための思考法を体験してもらった。セキュリティ上のリスクを認知してもらうためにプロンプトインジェクションによるパスワード奪取ゲームも行っている。
LLMが確率的言語生成モデルであることを解説した後、LLMの各種パラメータ(TemperatureやTop-P/Kフィルター等)を様々に変えてのアウトプットの変化を観察することも体感してもらっている。
講義後には、知識の定着のために以下のような課題を課している。
・講義で十分には理解できなかった箇所を生成AIで調べる。どのようなプロンプトを作成したか、その際、何を意識して設計したかを書き出して提出。
・SBI生成AI利用ガイドラインを読み、「機密情報」に関する内容を300字程度でまとめる。
・生成AIに以下の情報を出力させるプロンプトを作成し、提出する。答えそのものをプロンプトで与えるのは禁止にしている。出力情報:{'会社名': 'SBIホールディングス', '本社最寄駅': '六本木一丁目', '創立年数': 26}

図表3 研修の模様:第1講
第2講
生成AIアプリケーション作成ではクラウドや仮想環境の利用が必須となるため、一般常識としてのクラウドサービス理解を含めて、実務家(SBI生命の情報システム部)が講義を行った。受講者は生成AIサービスの利用体験はあっても、パブリッククラウドを利用した経験があるものはごく一部であり、クラウドサービスというものが何であるか、世界がどれほどクラウド依存で動いているかを理解している者は少ない。
そこで、受講者がゼロ知識であることを前提に、1)クラウドサービスとは何か、2)クラウドとAIの関係性、3)SBIグループ企業でのクラウドの利用事例について講義を行った。1)の内容は一般的なものであるため、ここでの紹介は省略する。2)では、多種多様なLLMがマネッジドサービスとしてクラウドで提供されているだけでなく、顧客提供サービスを組み上げるに際してクラウドが高い優位性を持っていることが紹介された。仮想サーバ、データストレージ、データパイプライン、データ集計分析、各種の広義AI領域のサービス(機械学習モデル構築、画像認知、STT/TTS(Speech-to-Text/Text-to-Speech)、様々な自然言語処理)がパッケージとして用意されている点などである。
3)では、住信SBIネット銀行がAWS上にネットバンキングインフラを構築している概要や、SBI証券が国内株式取引システムのクラウド移行を行った事例が紹介された。SBI新生銀行では生成AIの活用事例として、Amazon Bedrock上でClaude 3.5 Sonnetを用いて、法人営業の業務効率化や情報・データの可視化、情報格差の削減を実現していることなどが紹介された。SBI証券の手数料ゼロ革命ほか様々なビジネス戦略をクラウド活用が支えていることを理解してもらった。また、SBI生命ではAWSを用いてコールセンターのAI化を図った事例などが、クラウドのアーキテクチャ図や処理フロー図の解説とともに示された。
最後に、クラウド開発を進める場合のポイントや注意事項など実践的なアドバイスも提供された。コンペでの実装に際して大変有益となるアドバイスだが、この段階ではそれを知る由もなく、振り返りの学び直しで気が付くことになる。
第3~4講の事前学習
研修後半はコーディングのハンズオンに入るため、Pythonの基本を習得する必要がある。ノーコード開発ツールやAIによるコード生成が如何に発展しようとも、この基礎スキルが欠落していては開発や保守、アップデイトはおぼつかない。
まず、自前のPCにPythonが動く環境を作り、Jupyter notebookからローカル仮想環境として立ち上がったPythonをWebブラウザを通じた対話型実行環境として操作する練習を行ってもらった。具体的には、Python Japanにある環境構築ガイドを指示ノートにそって独習してもらった。次に、同サイトの「ゼロからのPython入門講座」を最後まで演習してもらい、基本的な文法やコーディング方法を身に着けてもらった。
プログラミングの経験の有無で本自習のハードルは大きく相違する。経験がない者にとっては本研修の最大難関ポイントとなるため、座学の段階からチーム分けをしており、チームメンバーやAI・デジタル戦略推進部のメンターに相談してもらいながら、壁を超えていくチャレンジをしてもらうこととなった。予想通り、参加者の学びの進捗状況は様々であったが、最終的な脱落者は一人も出なかった。若手メンターが自由参加型の勉強会や相談会を適宜開催し、丁寧にフォローアップした点も効果的であった。
プログラミングに限らず、ビジネス英語や財務会計、ITやクラウド、データ分析などのスキル獲得をOJTのみで進めるのは難しい。学びの対象物にもよるが、何らかの自習行為がないと能力の蓄積には限界がある。IT企業であればIT研修体制やサポートがありうるが、一般企業において社員のITスキルをどのような手法で積み上げていくかは、大きな課題となっている。バックグラウンドが多様な参加者を対象とした本研修では、最低限のITスキルを揃えるため、前述の自習課題に加えて第3~4講のハンズオン実践で様々な工夫を施している。
なお、自習コンテンツと第3講のマテリアルは本レポートの筆者が担当した。開発環境の準備と第4講のマテリアルはAI・デジタル戦略推進部のスタッフが担当している。
第3講:開発環境の紹介
生成AIアプリケーションの開発では、「マルチモーダルLLMをAPI経由で動かし、アウトプットを得る」ことが基本動作となる。実際のサービスではLLMへのリクエストとレスポンスの一往復ではなく、さらに複雑なフロー処理が必要となる。まずは基本形の習得に主眼を置いたハンズオンを実施し、後述する応用系にもチャレンジした。応用演習ではビジネス業務に直結する事例を取り上げている。
こうしたハンズオンにはLLMと開発環境が必要となる。LLMはAzureにデプロイしたGPTのエンドポイントurl情報とAPI-Keyを提供した。これらの情報管理の重要性についてもレクチャーし、なぜ講義開始直前に提供され終了後に即クローズされるか(エンドポイントとAPI-Keyを変更)を理解してもらった。
開発環境については、SBIグループが2020年からデータ利活用・分析推進のためDataRobot社と資本提携し、機械学習やビッグデータ分析の環境を整えてきたことを活用した。具体的には、DataRobotが提供するCodeSpacesを参加者各自に開発環境として提供した(UIは図表4を参照)。CodeSpacesは、DataRobotプラットフォーム内でコード主体の開発・実行環境を統合的に提供する機能であり、従来から提供されていたNotebook環境(前述のJupyter notebook類似)を拡張し、複数ファイルの管理、永続的なファイルシステム、Git連携、統合ターミナルなどを備えた本格的な開発空間として設計されたものである。PC単体のローカル環境で利用されるJupyter notebookの標準コードフォーマット(.ipynbノートブック)だけでなく、一般的なコードを扱える汎用性を持つ。
本研修ではハンズオンに必要な機能に限定してCodeSpacesを提供した。多数のユーザに対して共通の機能セットを備えた実行環境を提供するためコンテナ技術を用いており、ユーザごとに分離された環境をコンテナ展開した。こうした特長は集合研修での利用に便利である。また、受講者がUNIX環境に習熟していなくとも、GUIで開発環境を簡単に立ち上げ、操作することが可能となる点も大きなメリットであった。
本研修の技術的な中核は、CodeSpaces上のPython Notebook環境から、Azure上のGPTにアクセスし、LLMをプログラムから制御する一連のプロセスを体験的に理解する点にある。2つのクラウドサービスを使っていることの理解も第2講を実践体験するかたちで進めることができる。
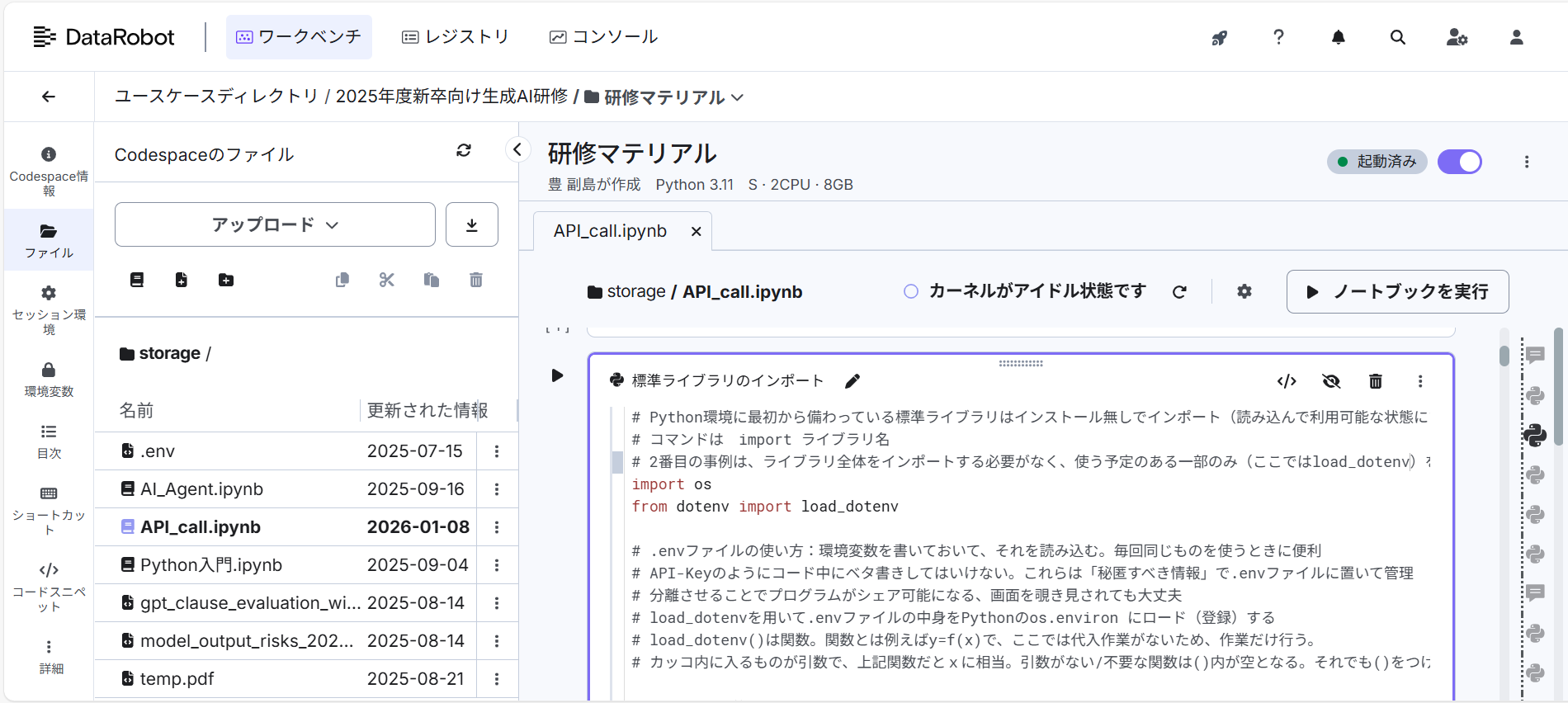
図表4 DataRobotのCodeSpacesイメージ
第3講:内容
ハンズオンの冒頭では、環境変数と設定管理の扱いを学習した。APIキーやエンドポイント情報をコード中に直接記述せず、.envファイルを通じて外部化している(図表4)。これは単なるセキュリティ配慮にとどまらず、開発・検証・本番といった複数環境を切り替えて利用する際の基本的な設計思想を理解させる狙いがある。生成AIを業務システムに組み込む際、こうした設定管理の巧拙が運用負荷やリスクに直結することを学べる構成となっている。
次に、LLMへのAPIリクエストとレスポンス処理を実行した。Pythonコードからモデルを指定し、プロンプトを入力として送信し、生成結果をレスポンスとして受け取る。単に「生成された文章を見る」ことが目的ではなく、リクエスト構造、レスポンスのデータ形式、ステータス管理といったAPIの基本要素を明示的に理解することを重視した。生成AIをブラックボックスとして扱うのではなく、「外部サービスの一種」として捉える視点を持つことを目的としている。
生成AI特有のパラメータ制御も実践した。temperatureや最大トークン数といったパラメータを変更し、同一の入力に対して出力がどのように変化するかを検証することで、LLMが確率的モデルであること、すなわち出力の再現性が保証されないことが理解できる。出力の揺らぎや再現性に対するリテラシーは、業務適用において極めて重要である。生成結果をそのまま業務判断に用いるのか、後段で検証・補正を行うのかといった設計判断は、こうしたモデル特性の理解なしには行えない。
次に、生成AIを単発で呼び出す段階から一歩進み、生成結果を変数として保持して後続処理に利用するフローを学んだ。これにより、LLMがアプリケーション全体の中でどのような位置づけにあるのか、すなわち入力データの加工、条件分岐、ログ保存といった通常のプログラム処理とどのように接続するのか、業務ロジックとLLMをどのように接続するのかを具体的にイメージできる。生成AIを「文章生成器」から「システム部品」へと位置づけし直す重要なステップである。
このように、ハンズオン研修は生成AIの最新技術を単に紹介するものではなく、API連携、クラウド実行環境、設定管理、確率的出力の理解、パラメータ制御、アプリケーション統合といった実務に直結する要素を一貫した流れで体験する点に特徴がある。生成AI活用がPoC段階から本格導入へと進む中で、これらの学びは、DX推進やAI活用基盤の内製化において重要な基盤となる。
ハンズオンの後半では、図表5に示したようなビジネス実践に直結する事例を扱い、受講者の関心と次のコンペステージへのヒントにもなるような題材を提供している。ちなみに、こうした例題の作成準備にも生成AIを活用している。図表6には二番目の事例のコードを示した。
|
外部ドキュメント自動取得と批判的分析 |
Web上のPDFからテキストを抽出し、要約のみならず論理的な矛盾や主張の根拠の弱さを特定する「批判的検討」までを自動化する手法を学ぶ。対象はBISのレポートで、ステーブルコインが金融システムにもたらす影響を検討したもの。 |
|
非構造データからの課題抽出と戦略策定 (図表8を参照) |
時系列の顧客対応履歴(遅延・返信なし・交換遅延・窓口混雑・返品状況不明などの時系列ログ)から、①問い合わせ要点(問題の種類・頻度)、②注意すべきリスク(感情・不満蓄積・信用毀損など)③推奨対応方針(表現の工夫・謝罪の要否まで)、を抽出する。不満の蓄積や企業信用への影響といったリスクを分析し、ベテラン担当者の視点で最適な次回対応方針を立案するシステムをプロンプティングで設計する。 |
|
Function Callingによる情報の構造化抽出 |
業務委託契約書ドラフトを題材に、LLMに不利条項(解除条件・損賠など)の抽出、そう判断した理由、修正提案を行わせる。JSON形式で抽出するFunction Callingを学び、システム連携を視野に入れた高精度な処理を体験する。 |
|
ドメイン知識を要する高度なリーガルチェック |
法務のプロでないと見抜けないような仕組まれたトラップがある業務委託契約書を用い、再委託制限、瑕疵対応期間、一方的解除、成果物定義における曖昧さの残存、準拠法の国内外ギャップなど、専門知識が不可欠な「隠れたリスク」を指摘させ、リスクが存在する根拠を解説し、対案としての契約書を作成するシステムを体験する。これを保存し次の課題に利用することで、複雑な業務フローへの対応を体験する。 |
|
AIによる成果物の自動評価と品質管理(LLM-as-a-Judge) |
上述の課題でAIが生成した回答を、人間が用意した正解リストと自動照合・採点させ、1)最も近いチェックポイント番号とそう判断した理由、2)契約法観点からの妥当性スコアリング(1~5点)とその判断理由、について生成AIに作成させる。業務の効率化とアウトプットの品質担保を両立させる手法を学ぶ。 |
図表5 実務を意識した実践的なハンズオン
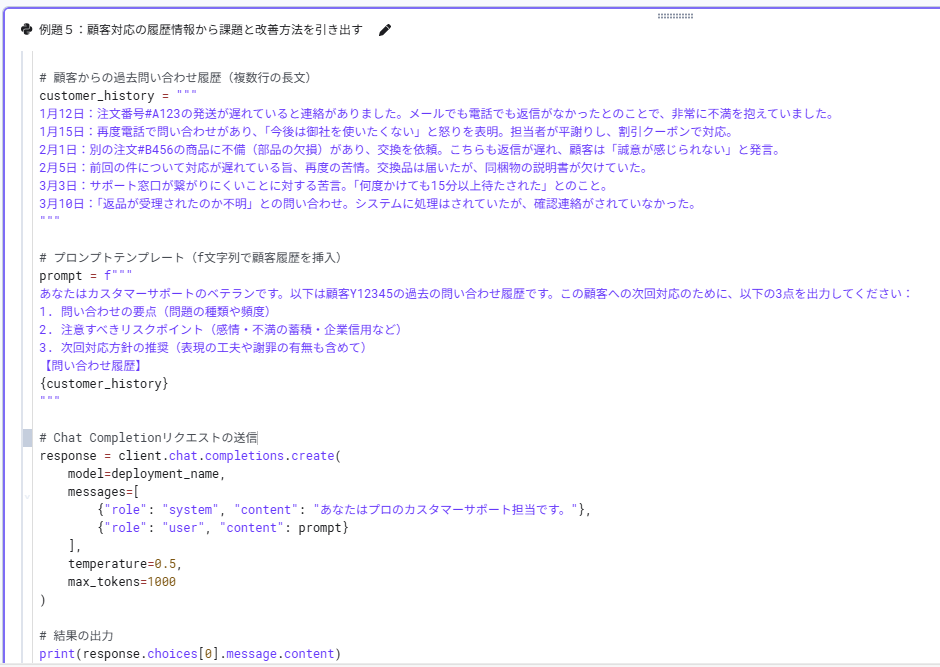
図表6 顧客対応履歴から要点・リスク・改善点を抽出
第4講の事前学習
第3講のハンズオンでは、解説とコードをnotebook形式で配布し、開発環境のターミナルでコマンドを打つことなく、対話型実行環境でPythonコードを順次実行できる環境を用意した。しかし、アプリケーション開発になると、ターミナルでUNIXコマンドを操作したり、プログラミングにおける関数やクラス概念の理解と具体的なコーディング法を理解しておく必要に迫られる。
ここでの事前学習では、以下の課題を自習してもらった。前回の事前学習と同様に、チーム内での相談やメンターによるフォローアップも用意された。
1)実行環境の遷移:対話型実行環境からバッチ方式へ
実際のアプリケーション開発では、プログラム全体を一括実行する「バッチ方式」の理解が不可欠となる。CodeSpacesのLinux環境でバッチ方式の.pyファイルの作成と実行を行えるよう学習マテリアルを用意した。CLI操作の基礎として基本コマンドを実践し、テキストエディタで記述した.pyファイルをCLIから実行する手順を確認した。
2)コードの構造化:関数の重要性
コードの再利用性と可読性を高めるための関数(Function)の基本構造を学び、実践した。
3)オブジェクト指向の基礎:クラスとインスタンス
AIエージェント開発フレームワークを理解する上で避けて通れないのがクラス概念である。クラス、インスタンス、属性、メソッドなどをカプセル化して管理する方法やコンストラクタなどの重要概念を実践付きで学習した。
これらは、単純なスクリプト記述から、モジュール化・オブジェクト指向を意識したエンジニアリングへのステップアップに必須のものである。特に、関数やクラスを自作する経験は、既存のライブラリ(Azure OpenAIクライアント等)がどのような構造で動作しているかを理解する一助となる。
第4講:内容
生成AIを活用した自律型AIエージェントの設計と実装訓練を行い、マルチエージェント・システムの技術的側面とその実装手法について解説を行った。最初に重要概念の講義を行っている。比較的新しい技術内容であり、本レポートの読者も関心があるかもしれないので、その中身を紹介する。
エージェントとは、単なる対話型のチャットボットではなく、ユーザに代わってワークフローを自律的に実行するシステムを指す。従来のRPA(Robotic Process Automation)が固定されたルールに基づく自動化であったのに対し、AIエージェントは生成AIの推論能力を活用することで、複雑な判断、頻繁に更新されるルールへの適応、および自然言語ベースの情報処理を可能にする。
エージェントを構成する技術的3要素は以下の通りで、まずは、これらの概念を解説した。
・Model:推論と意思決定を司るマルチモーダルLLM
・Instructions:役割、制約、プロンプトを通じたワークフローの定義
・Tools:外部APIや検索エンジンなど、現実世界へ働きかけるための「手足」
エージェントをイチから開発するのは不効率である。実装にはクラウドサービスやフレームワークライブラリを活用する。第3講では、Azure OpenAIとAgent SDK(OpenAIが提供するエージェント開発を支えるフレームワークコンポーネント群)を利用した。第4講では、Google Cloudが提供するAIプラットフォームVertex AIと、エージェント開発用フレームワークであるGoogle Agent Developer Kit(ADK)を採用している。同SDK(Software Development Kit)を利用することで、ツールの定義、セッション管理、エージェント間のオーケストレーションを抽象化し、高度なワークフローを効率的に記述することが可能となる。
演習1:エージェントを動かす
ハンズオンではADKを用いて最小構成のエージェントを実装するところから始めた。エージェントの機能は、「与えられたテーマ・議題に向けて、ポジティブな面から意見を述べる」ものとした。
コーディングの視点から解説すると、Agentクラスをインスタンス化し、InMemoryRunnerを用いてRunnerというクラスにエージェントを登録し、これを通じて実行を管理する。技術的に重要なポイントはセッション管理となる。LLM自体はステートレス(状態を保持しない)であるため、会話のコンテキストを維持するにはLLMの外部で履歴を保持し、リクエストごとにモデルへ送る必要がある。ADKのInMemoryRunnerは会話履歴を保持する仕組みを提供し、ユーザごとの一貫した対話を実現している。
ハンズオンでは、1)受講者がインストラクション(与えられたテーマについてポジティブな意見を述べるよう指示)をコード中に書き込み、2)エージェントをRunnerとしてインスタント化した後、3)これにメッセージ(具体的なテーマ設定)を与えてエージェントを動かし、4)どのような形で会話履歴が保持されているのか、セッションの中身を覘いて確認することを行った。
演習2:エージェントにツールを与える
LLMは文字を出力するだけであり、web検索やファイルを操作することはできない。エージェントの「手足」となるツール利用は、生成AIが直接APIを叩くのではなく、関数を呼び出すためのコード(またはJSON形式の指示)をLLMが出力することで実現される。LLMが書いたコードを実行する仕組みを外で組んでおけば、あたかも生成AIが関数を実行したように見せることができる。この仕組みがツールである。
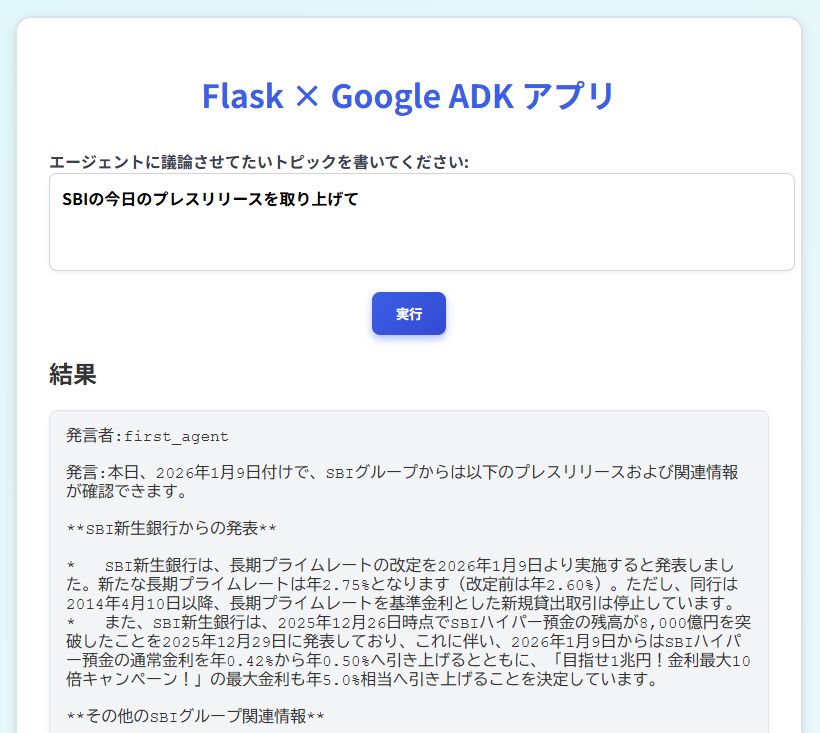
こうした理解のもとで、前述のポジティブ議論エージェントを拡張し、議論を活性化させるファシリテーター機能も兼ね備えたエージェントを実装した。エージェントの役割は、ディスカッションテーマについて議論の認識共有を図り、議論の活発化のために必要な情報を収集して提供し、議論が出尽くしたのち各参加者の主張にスコアを付すというものである。検索を行うため、GoogleのADKから検索ツールを組み込みで利用している(注意:この段階では一つのエージェントに上記の機能を全部詰め込んでおり、後に機能分解していく)。
完成したものに「今日公開されているSBIHDのプレスリリースを1つ検索して、議題に取り上げて討論してください」というメッセージを与え、作成したエージェントの機能を確認した。
演習3:マルチエージェント・システムへの拡張
単一のエージェントに全てのタスクを詰め込むと、ステップが多数となり条件分岐が増えるなどワークフローが複雑化する。これに伴い精度も低下しがちになる。コードの見通しを善くするという観点からも、複数のエージェントに役割を分担させた方が望ましい。
そこで前述の課題を発展させてマルチエージェント・システムを実装する演習を行った。具体的には、ポジティブな議論を展開するエージェント、逆にネガティブな論陣を張るエージェント、議論のファシリテーターとスコア判定エージェントの3つに分解した。なお、ツールについても、検索エージェントや検索条件を生成するエージェントなどに機能を分化させることで、ツール選択の失敗が抑制可能となる。
実装では、Google ADKに用意されているSequentialAgentクラスを用い、複数の役割を持つエージェントをシンプルに直列に繋ぐワークフローを作り、実際に動かしてみる演習を行った。
演習4:Flaskを用いたWebアプリケーション化
いよいよ最終課題である。ここまでで構築したマルチエージェントをWebアプリケーションへ統合するプロセスを学ぶ。WebアプリケーションのフレームワークとしてFlaskを用い、サーバーサイドでエージェントを呼び出し、フロントエンド側でユーザと対話させることで、実運用可能なAIサービスとしての形態を整える。
まず、Webアプリケーションのフレームワークの用法に習熟するため、Hello, World!をブラウザ表示させるだけのWebアプリを作成した。ブラウザからのリクエストがWebサーバに送られ、アプリケーションサーバーでHello, World!を返す関数が動き、レスポンスがブラウザに表示されるというシンプルな構造である。この演習によりWebアプリケーションシステムの基本的な全体像を理解することができる。リクエストやレスポンスを扱うためのGETメソッドやPOSTメソッドの学習も行っている。
次に、これを動的なWebサイトに変更するため、時刻など状況に依存した情報を含むhtmlが返ってくるような拡張を行った。そのうえで、適宜の指示により生成AIがhtmlを書き換えて返すような拡張を施した。例えば、時刻や情報更新ボタンを含めるよう変更した動的htmlを、もっとクールなデザインに変更するような指示を与え、これを生成AIに実行させてコードを書き換えることでWebアプリをアップデイトする演習を行った。
最後に、テーマ討議を行うマルチエージェント・システムをWebアプリケーションとして実装した。ターミナル上でバッチ方式により動かしていた前述のテーマ討議システムが、Webブラウザから実行可能なことを確認している。図表7では、与えられたテーマ(SBIの本日のプレスリリース)に関する材料をネットから収集している様子が示されている。図表8では、上記テーマと材料についてポジティブ・ネガティブ議論が陳述された後に(当該部は省略)、第三のエージェントであるファシリテーターAIが議論を展開・発展させてしている様子が示されている。
エージェントフレームワークADKを用いたマルチエージェントの構築経験は、複雑なビジネスプロセスの自動化において高い応用価値を持つものであり、コンペではその応用が期待される。もちろん、作成したいアプリケーションの機能や使いたい生成AIサービスコンポーネントに応じて、LangChain/LangGraphのような汎用フレームワークや、OpenAIのAgents SDKを利用することも考えられる。例えば、Google Vertex AIを利用する構成であれば、第4講で利用したGoogle ADKが相性がよいであろう。
図表7 AI駆動のテーマ討議Webアプリ(1)材料収集
注)研修実施日は2025年秋であったが、本レポート作成用に後日、同一課題を与えたため、2026年入り後のプレスリリースを討議テーマとして収集している。

図表8 AI駆動のテーマ討議Webアプリ(2)ファシリテーターAIのOutput
おわりに
以上が新入社員垂直離陸型の生成AI研修のコンテンツである。注目すべきは、コーディングの経験がゼロの受講者であっても、短期間のうちに生成AIアプリケーションの開発が「体験できる」ようになったという点である。これを可能としたのは、生成AI関連のツールやフレームワークが爆発的に進化した(現在もさらに発展を続けている)ことにある。
もちろん、即席養成コースであるため重要な知識やスキルの習得を省略している。「開発が体験できる」と「開発ができる」の間には大きな隔たりがある。しかし、高いゴール設定を行い、爆速でリフトオフする体験は、「自分でも作れるのである」という強烈な意識づけをもたらす。内製化への第一歩がここにある。この体験をもって、次のステージであるアプリ開発コンペが既にスタートしている。
開発の民主化・ビジネス現場への移行は、生成AIをシステム化する技術の進歩によって更に加速するであろう。マルチモーダルLLM本体の能力拡大が注目されがちであるが、これをユースケースとして実装するための技術革新も重要である。
こうした動きが続くことにより、ITインフラの身の回り開発は今どきのビジネスパーソンの基本素養になっていくと思われる。まずはSBIグループの未来を担う若者から学びを開始し、これを中堅ベテラン層に拡大していくことが、組織横断的なAI・デジタル戦略推進部の主要タスクのひとつとなっている。実際、グループ企業内で様々な取り組みが始まって久しい。その取り組みや効果の紹介は別の機会としたい。