2025年10月24日
研究者のための生成AI講座(その1)
―研究工程の分解と生成AIツールの活用―

生成AIによる研究の効率化と自動化
sakana AI社が2024年8月に公表したAIサイエンティストは、人工知能が研究計画から論文執筆までを完全自動実行するという衝撃的な新しい研究スタイルを提示した。アップデイトされたAI Scientist-v2が作成した学術論文は、世界トップレベルの機械学習の学会(ワークショップ)で査読プロセスを通過し、AI業界で世界的なニュースとなった(2025年3月、詳細はこちら)。
このように研究プロセス全体を自動実行する試みが先端的なAI研究者や企業によって推進されているが、それだけではない[1]。大規模言語モデル(LLM)を活用した多様な生成AIサービスが登場し、これが研究の進め方に大きな技術革新をもたらしつつある。
例えば、文献サーベイを大幅に効率化・高度化するサービスが挙げられる。また、LLMのDeep Research機能は研究計画の策定に有効である。2024年末に登場した同機能は、質問にすぐ回答するのではなく、考え方や作業手順を整理し、外部情報も収集を行ったうえで情報を統合して回答を作成するものであり、研究の様々な局面で活用ポテンシャルを有している。
文章だけでなくコード(プログラム)生成の能力も著しく高まっており、分析用プログラムの作成や検証、バグ取りも生成AIが手助けしてくれるようになった。言葉で指示することでソフトウエア・アプリケーションすら開発できる時代になっている。データを与えると、その特徴を自動で分析してレポートにまとめてくれることも可能になった。このように、研究テーマの探索から分析、論文の執筆、プレゼンテーション資料の作成、英語スピーチの準備まで、研究の各過程において生産性や質を高める様々な生成AIサービスが次々と誕生している。
本稿では、研究の完全自動化ではなく、研究工程の全体指揮(オーケストレーション)や各工程での作業方針は研究者自身が策定することを想定している。こうした従来型の研究プロセスにおいて、研究や学習行為に生成AIをどう活用できるのか、最新の生成AIサービスを紹介しながら「新しい研究推進法の模索」を実践してみる。
本稿はその実践シリーズの初回であり、以降、研究工程の順にそって活用事例の紹介を行っていく。初回は、1)研究の工程分解と各工程で活用できそうな生成AIサービスのリスト紹介、および、2)リサーチテーマ探索のデモである。なお、生成AI技術は「四半期ひと昔」で劇的な速度で進歩しており、紹介した内容の陳腐化も著しく早い点を最初に断っておく。
学習や研究への生成AI活用については、様々なガイドラインが研究教育機関や公的機関から公表されている。著作権や知的財産権、プライバシーへの配慮、開示・説明責任、正確性・再現性、盗作剽窃、情報セキュリティ、研究スキル向上へのプロ・コンなどが論点や留意点として挙げられている。
これらに加え、技術や社会状況の変化に対応したガイドライン更新の重要性も同時に指摘されている。四半期ひと昔という超高速の技術革新のもとで、デジタル化社会における倫理や社会常識、価値観も変容を続けている。研究や教育もそうした大きな流れのなかにある。大切なのは、使いながら考えていくことであろう。
研究の工程分解
製造業のみならずサービス業、ソフトウエア・システム開発では、製造・サービス工程の分解がビジネスモデル改善の基本ステップとなっている。一方で、研究活動では必ずしもそうしたオペレーション解析は定着しておらず、大学院や研究室におけるOJTで習得していくことが多い。とくに人文・社会科学系の研究でそうした傾向が強いように思われる。
そこで、最初に金融経済分析を事例として標準的な研究工程の分解を行い、各工程でどのような生成AIサービスが活用可能なのかを生成AIに分析させてみた。具体的には、GPT-5のThinkingモードとGemini 2.5 Deep Researchに以下のプロンプト1を与え、返ってきた結果を参考に追加調査を行い、筆者が知る情報やリサーチ経験を参考に整理・加筆修正した。図表1がその結果である[2]。
プロンプト1
「金融や経済を対象とした学術研究において、分析対象のサーチから論文執筆、プレゼンテーション、ジャーナル投稿までの一連の研究工程をステップごとに分解して表に示してください。その各工程で、どのような機能が生成AIサービスの活用によって効率化され、高度化されるのかをまとめ、先に作った表に対応するよう別の表にまとめてください。最新の生成AIサービスもカバーするよう検索してください。利用者が多いメジャーな生成AIサービスを取り上げてください。」
(注)2つの作業を別の表に分けるよう指定したのは、Webブラウザ上での見やすさ目的のためである。図表1では内容を統合したものを示している。
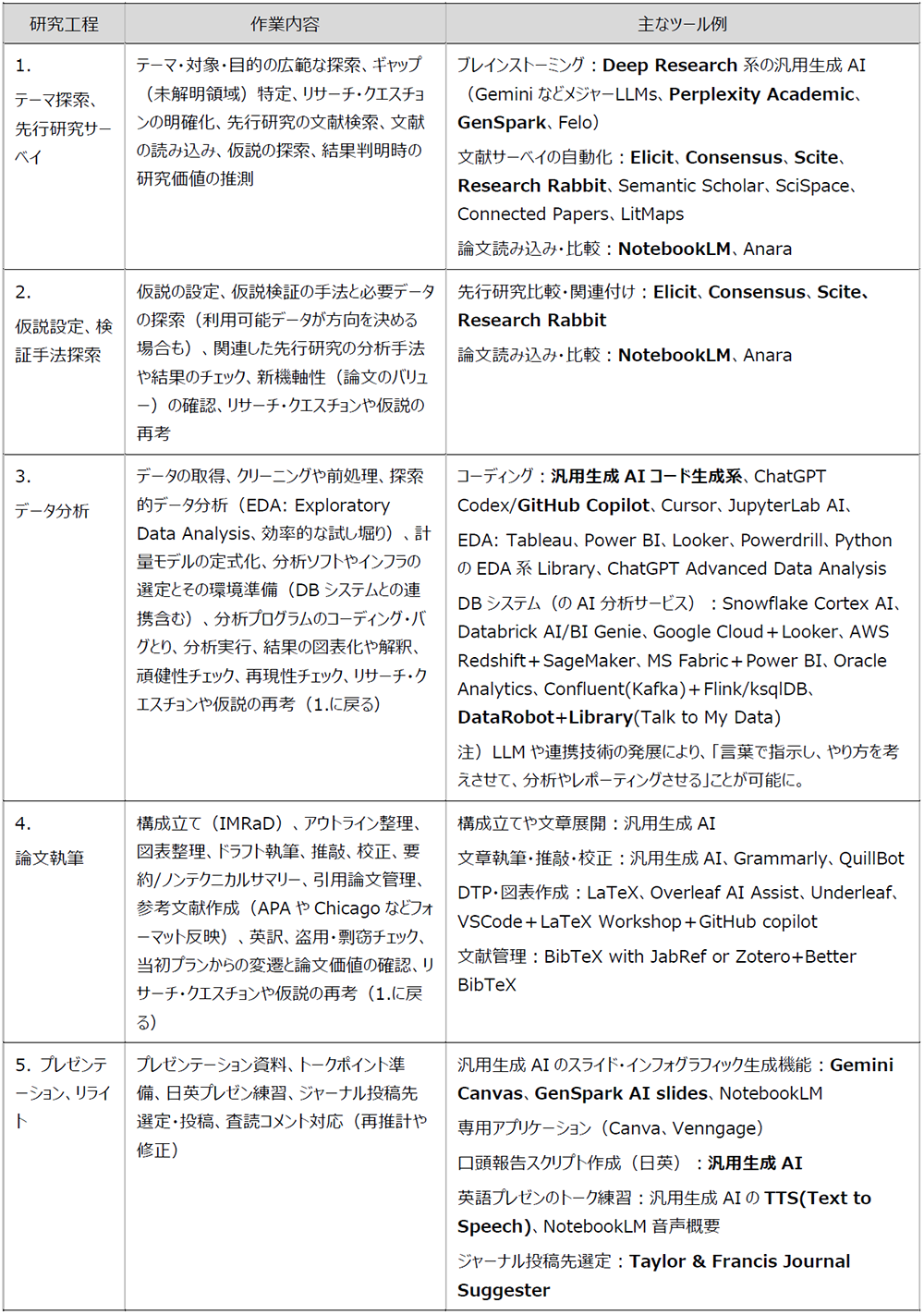
図表1 研究工程の分解と生成AIの活用例
注)太字で示したアプリケーションを本シリーズで紹介していく予定である。
テーマ探索という最初の壁
学術研究においては優れた研究テーマの発見やリサーチ・クエスチョンの設定が重要となる。テーマ、対象物、目的を広範に探索し、先行研究の文献検索を行い、読み込むことで先行研究間の関連性をマッピングする。これをもとにギャップ(未解明領域)を特定し、リサーチ・クエスチョンを明確化することが最初の大きな課題となる。
クエスチョンへの仮の答え、いわゆる仮説をどう立てるかという探索においても、その仮説が分析によって肯定・否定された場合の研究価値を推測するというマーケティングセンスが必要となる。バリューがある研究が何であるかを掘り当てることは、当該分野の研究蓄積が十分にない研究者にとって容易ではない。
その点、生成AIは、人類の膨大な知的資産を巨大なテキスト群、例えば、著作権が切れたすべての書籍やネット上で閲覧可能な情報を学習している。医学や化学、物理、各種工学、生物学、法律、経済、統計、歴史、文学およそ考えられるあらゆる分野の情報を、LLMの巨大なモデルとそのパラメータ空間に蓄積している(詳細は副島[2024]を参照[3])。
これを活用することで、曖昧模糊とした対象選定や動機からスタートしたとしても、研究テーマ探索を効率的に遂行することができる。最初に情報量が一つしかないプリミティブな問いから始めてみよう。
プロンプト2
「家計の資産選択行動を研究テーマとして考えてみたいです
このプロンプトを生成AI(Gemini 2.5 Flash)に与えたところ、図表2に示すように「このテーマには様々な切り口があり、」と分析視点の事例集を返してくる。同じプロンプトを用いた別の試行では、「どのような目的で家計の資産選択行動を分析されたいか、もう少し詳しく教えて頂けますか?」と追加情報の提供を求めてきた。生成AIが壁打ちの相手方になることはビジネス用途でも広く知られている。
ちなみに図表3のように厳しい指導教官モードで依頼すると、「リサーチ・クエスチョンが明確でない」という指摘に続けて、上述したようなテーマ探索に関する指導を返してきた。なお、図表1と異なり、図表2以下では生成AIの回答のレベル感を確認するために、加筆修正せず回答をそのまま示している。

図表2 汎用生成AIとの壁打ち

図表3 厳しい指導教官版
次に目的情報や対象を明確にしたプロンプト3を与えてみた。図表4がその結果である。一歩前進して、リサーチ・クエスチョンの特定に関するアドバイス(練習課題)が返されている。役割設定をプロンプトで与え、回答者の立場を変えることでも様々な回答バリエーションが試せる。
プロンプト3
「目的は政策提言です。資産クラスは株式や投資信託です。年齢、所得階層、学歴、職業、年収、居住地域、家計構成員、金融リテラシー、リスク回避度など、家計の属性が投資行動にどのような影響を及ぼすかに関心があります。行動経済学の視点から政策的なインプリケーションを導き出したいと考えています。」

図表4 目的の絞り込み版(厳しい指導教官設定を継続)
生成AIは一回で相当量の情報を提供するが、テーマの段階的な絞り込みや深堀りを一度の連続壁打ちで終わらせるよりも、繰り返し実施することで異なる視点でのテーマ探索が可能となる。また、分析者と生成AIが対話的に議論を進める以外にも、生成AIが返してきた結果を生成AIに評価させる手法もある。これは、テーマ探索だけでなく分析手法の選択や結果の解釈においても有益な方法である。
なお、生成AIの基礎になっているのは確率的生成モデルであるため(前出の副島[2024]を参照)、同じ生成AIモデルに同一の質問を繰り返し問うことも有益である。このほか、異なる汎用生成AIモデルを活用することで検討のバリエーションを高める方法もある。図表1のサービス事例に示したGenSparkは、複数のLLMやAIエージェントをタスクの種類や複雑さに応じて組み合わせて利用し、得た情報を統合して回答する方式を採用している。
生成AIの回答を生成AIに検証させる試みをChatGPT-5(instant mode)で行なってみた。まずは以下のプロンプト4を与え、図表5の回答を得た。この回答に対してプロンプト5で再検証をリクエストし、返ってきた回答を図表6に示した。批判的な検討リクエストが機能していることがわかる。
プロンプト4
日本の家計の金融資産選択行動をテーマとして研究を考えています。目的は政策提言です。資産クラスは株式や投資信託です。年齢、所得階層、学歴、職業、年収、居住地域、家計構成員、金融リテラシー、リスク回避度など、家計の属性が投資行動にどのような影響を及ぼすかに関心があります。行動経済学の視点から政策的なインプリケーションを導き出したいと考えています。リサーチ・クエスチョンの立て方を幅広く検討してみてください。A4縦1枚に簡潔に収まるよう回答してください。
プロンプト5
今、回答をもらった内容について、批判的な立場や、視点を拡げるような建設的な立場から、コメントを作成してください。A4縦1枚に簡潔に収まるよう回答してください。

図表5 ChatGPT-5の回答

図表6 回答の再検討
図表1の項目1.に示した生成AIサービスには、一度のプロンプトで完成度の高い取りまとめレポートを作成するものがある。Deep Research機能を持つ生成AIでは、ユーザの壁打ちや段階的検討に類似する行為を生成AI内部で実行する仕組みが採用されている。例えば、最初に大まかな検討方針を考え(この段階でユーザに確認や修正を求めてくるサービスもある)、ネット環境で情報を収集し、得た情報を総合的に検討して、再度、情報収集と情報統合を繰り返すことで、最終的な回答の質を上げていく方法などである。
図表7は、テーマ探索の視点が多少絞れてきた段階でGPT-5のDeep Researchを用いて作成したものである。出典先へのリンクが示されており、検索エージェント機能による先行研究の自動収集が行われていることがわかる。テーマ探索と先行研究のサーベイは不可分であり、往復運動を繰り返すことが一般的である。次号では、文献サーベイに特化した生成AIサービスを取り上げ、デモ内容を含めて紹介する。

図表7 Deep Research機能を用いた回答
最後に、図表1に示したようなプロセスを研究工程が直線的に進むことは「まず無い」点に触れておきたい。工程の2.以降のすべてに「リサーチ・クエスチョンや仮説の再考」を含めている。最初の工程を丁寧に行ったとしても、文献サーベイやデータ収集や分析手法の選定、分析実行、結果の解釈など様々な段階で、「最初のリサーチ・クエスチョンや仮説のセットアップが適切ではなかった」と気が付くことが頻繁にある。論文の執筆中に、より優れたリサーチ・クエスチョンや仮説を発見することもあり、最初に立ち返って研究を最初からやり直すことも少なくない。
しかし、一直線に順調に進展した研究ほど振り返ってみるとつまらないと感じることのほうが多いように思える。ループしたりスパイラルしながら、視点や目的、手法、データ、分析結果のセレンディピティに出くわしながら、右往左往しつつ進んでいく方が面白い研究が得られるような気がしてならない。やり直す勇気、捨てる勇気は大事だと思われる(個人の感想です)。
そして、研究工程を高速化・効率化する生成AIサービスは、試行錯誤や改善の可能性を大きく拡げてくれる。生成AIの活用は、研究の競争力強化には必須のスキルセットとなっている。
[1] 例えば、Anton Korinek, “Generative AI Agents for Economic Research (August 2025 update),” Journal of Economic Literature, 61(4), Dec 2023.や、Jiabin Tang, et.al., “AI-Researcher: Autonomous Scientific Innovation,” arXiv:2505.18705v1, 24 May 2025.などが挙げられる。研究遂行のツールでなく、研究の素材とするアプローチもある。高橋・大高・加藤の「生成AIの経済シミュレーションにおける応用可能性」日本銀行リサーチラボ、25-J-1では、LLMを経済エージェントとして活用し、シミュレーションによって企業の価格設定行動や消費者の価格弾性値、寡占・独占市場での価格設定行動の比較などを行っている。エージェント・シミュレーション分析の歴史は古いが(金融市場への応用例のサーベイはこちら)、エージェントの行動様式の設定や、エージェントが行動するワールドモデルに技術革新が生じたことで、その潜在力は急速に拡張している。日経新聞社のイベントGenAI/SUM 2025の1セッションでは、SBI金融経済研究所の所報8号で特集した「因果推論の最先端」を取り上げ、寄稿者の和泉教授(東京大学)と本稿筆者がそうした可能性を論じている。例えば、因果認知に個人差や癖があり、それを計測・定量化して生成AIでエージェント化することができれば、経営者や市場参加者、SNS利用者の間に生じる相互作用によって生産活動や市場変動、世論が変遷していくダイナミクスを検証することが可能となる。膨大なデジタルデータから個人や企業のペルソナや認知の癖・バイアスを検証する技術も自然言語処理や生成AIの技術革新によって可能になっている。
[2] 前出のAnton Korinekの論文のTable1では研究活動をリサーチタスクに分け、汎用生成AIやエージェント型チャットボットのサービスで可能な作業が示されており、本稿の図表1と類似している。ただし、具体的なサービス名や使用事例は示されていない。同論文はAIエージェントによるリサーチの自動執行を目指したものであるが、より正確には冒頭に紹介したsakana aiの全体自動執行型と本稿の研究者オーケストレーション型の中間に位置すると思われる。本稿は、研究の各工程における多種多様な生成AIサービスの活用を目的としており、サービス群の紹介や応用事例において情報量が多い。
[3] 「生成AIウォークスルー:基本技術、LLM、アプリケーション実装」、SBI金融経済研究所「所報」6号、2024年8月。コンピューターが言語をどのように読み込み、生成するのかを、基本から始めて2024年前半までの技術発展を解説している。ブレイクスルーとなった主要モデルやコンセプトを網羅した展望論文である。